
By Kaitlyn Baker
Web scraping is a significant tool to have when considering the acquisition of data from online sources. A web scraper can be designed to extract data from one or more websites to be used as information, such as product pricing and comparison, movie and theatre information, or gaming data. The web scraper used in this project was built for the Baltimore organization called Return Home, whose mission is dedicated to helping previously incarcerated citizens return to Baltimore. Return Home has developed a website that compiles a wide range of resources for returning citizens such as housing, food, job training, addiction counseling, and more. More information can be found on their website at returnhome.org.
The system that Return Home currently uses to display the contact information of all the resources on their website works off of static address and phone numbers that have been manually entered into a spreadsheet. The web scraper currently in place is triggered each day and sends a report out noting if each site is responding. The language used to code the scraper is Python and Google Sheets is used to store data.
The issue with the current system is that there is no way to know that an organization changed their contact information since the contact values displayed are manually entered. The information change would have to be detected by manually crosschecking each organization’s contact info with the info that is in the spreadsheet. To resolve this issue, we turned to using XPath expressions to update Return Home’s website with the most current information. XPath is a language that points to a specific piece of data contained within an XML document and an XPath expression is the mechanism that allows one to target specific data within the XML document. A specific language is used, and an expression is created to target the specified data.
For each resource Return Home adds to their website, the web scraper targets the XPath expression of both the address and phone number listed on a website and displays that contact information on the Return Home website. This tool is a way to ensure Return Home’s website stays up to date with information provided to the user.

The XPath expression for both address and phone number were targeted and copied from each resource’s website and added to the Google spreadsheet. To find the XPath expression for a specific piece of data, target the information needed, right click on the specific piece, and click “inspect” to pull up the developer tools. From here, right click the target data from the developer tools, hover over “Copy”, and click “Copy XPath”, similar to the figure displayed here. This copies an expression that points the web scraper to the data it needs to gather.
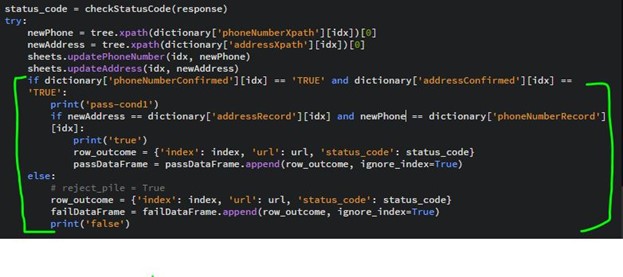 To further improve the accuracy of this web scraper, we added code that compares the currently scraped values to the previously scraped values. This is displayed in the code snippet above, in the green brackets. The intention of this is to help ensure that if any value that is being collected changes, the web master will be alerted and can check to see if a course of action needs to take place to solve the issue.
To further improve the accuracy of this web scraper, we added code that compares the currently scraped values to the previously scraped values. This is displayed in the code snippet above, in the green brackets. The intention of this is to help ensure that if any value that is being collected changes, the web master will be alerted and can check to see if a course of action needs to take place to solve the issue.

We then clean the data by removing any extra spaces and letters from the values collected (red arrows) and those values are then updated in the corresponding columns of the spreadsheet (green arrows). The updated contact information values are then updated on the Return Home website.
There are a few lessons to note of the challenges involved in working with a web scraper and XPath expressions. All websites are different and may require extra work to gather relevant data. There may be times where a one-size-fits-all web scraper cannot be used. Gathering data from a dynamic website, one that relies heavily on JavaScript or ajax for example will require extra work to target the data that’s needed. Also, it’s not always possible to extract meaningful or quality data from every website. The information a person needs to extract may not be listed on the website entirely, or the data is buried in a block of text. Data cleaning is an absolute necessity for this and was implemented in this project for this very reason. Finally, websites change without notice and the data a person is targeting on a site may move and require retargeting of the XPath expression. Aside from these challenges, web scraping XPath expressions can bring a large amount of progress and effort to the table with just a few clicks. By speeding up the time it takes to gather information and the ability to automatically update a database with current information, this tool can be an asset to gathering and maintaining a scalable amount of data without the need to frequently crosscheck and manually enter updated data.