
By Kabah Selli
Background:
The City of Baltimore has a system called “Open Checkbook Baltimore” wherein they publicly publish the various transactions that the city has made over the course of a fiscal year (a fiscal year defined by the city as beginning July 1st, ending June 30th). Open Checkbook Baltimore is a dashboard created using Microsoft Power BI, which is a visual data representation tool. This dashboard has a plethora of interactable graphs, charts, filters, and other features that allow users to narrow down and find specific spending metrics of Baltimore City. Currently, the city has made two fiscal years’ worth of data publicly available through Open Checkbook Baltimore. (For the sake of simplicity will be referred to as OCB.)

This service specifically was introduced by Mayor Brandon Scott; thus, it is a service created and managed by the Mayor’s Office. This is not a new concept as various other cities have had their own Open Checkbook programs and dashboards; New York City has the most renowned version of this system dating back to 2010.
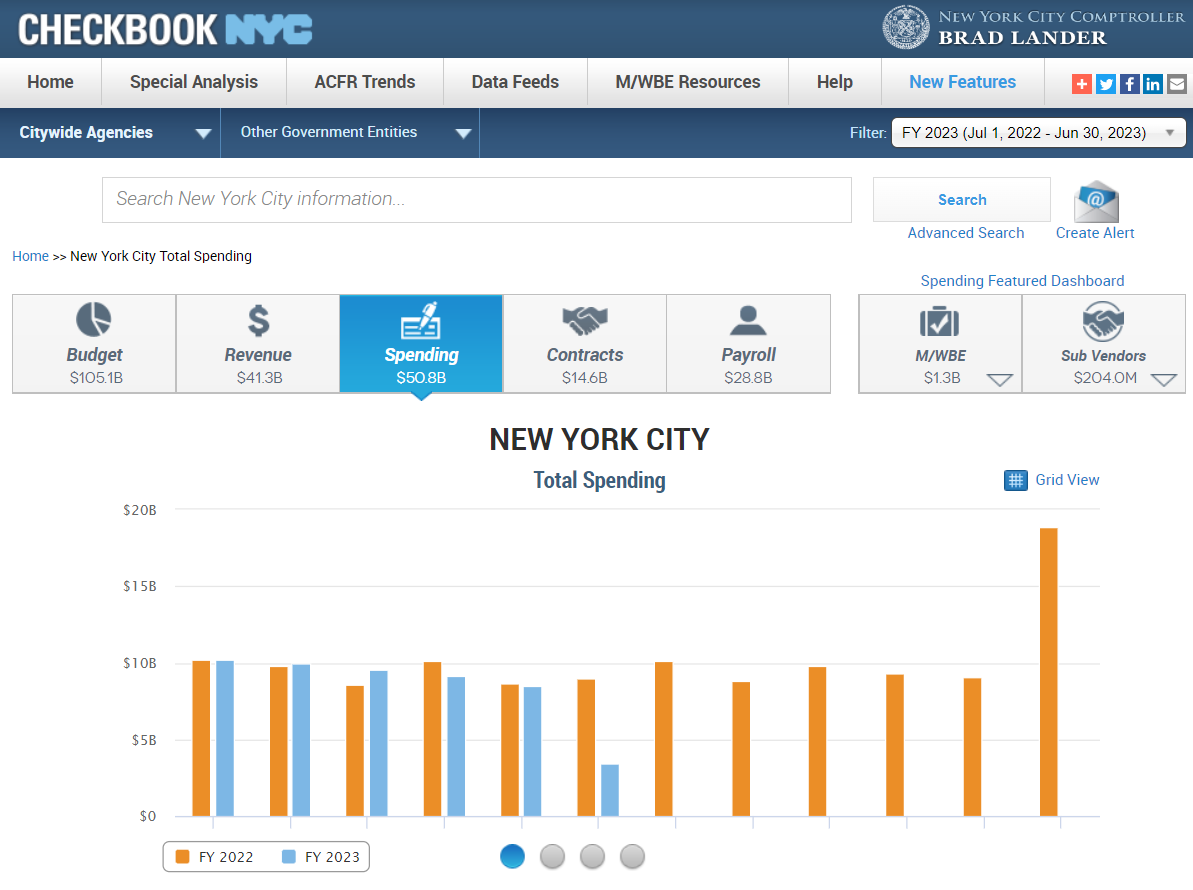
While this level of transparency is great as it allows citizens and taxpayers alike to see exactly what the money is going towards within the city, the biggest problem that I noticed is that it didn’t exactly show where the money is going. To be more specific, the type of data that was missing from this dashboard was location information. This data is usually a searchable address, a neighborhood, or zip code, even a set of longitudinal and latitudinal coordinates. The main thing is that while this system may break down the City’s spending, it doesn’t do a great to inform users where this money is spent.
With that key metric not present, it was my goal to come up with a system that would generate that location data based upon the data already provided by the Mayor’s Office. I also set out to answer the key data science question of “Is it possible to extract/ generate location data from a pre-existing database?” This was an ambitious project from the onset, but I was ready to take on such a challenge as the findings from this project held great implications for future data science projects.
Methodology:
In order to go about creating such a system and answering this question, I first had to understand what type of processes would be involved. I started with my main method of data collection, which involved web searching. The OCB data while on a dashboard made via Power BI, wasn’t much help to me, especially with me adding new data it. As such, I was able to download and work directly within the source data which was a Microsoft Excel Workbook.
(For simplicity, this Excel Workbook will be referred to as The Database or OCB Database)
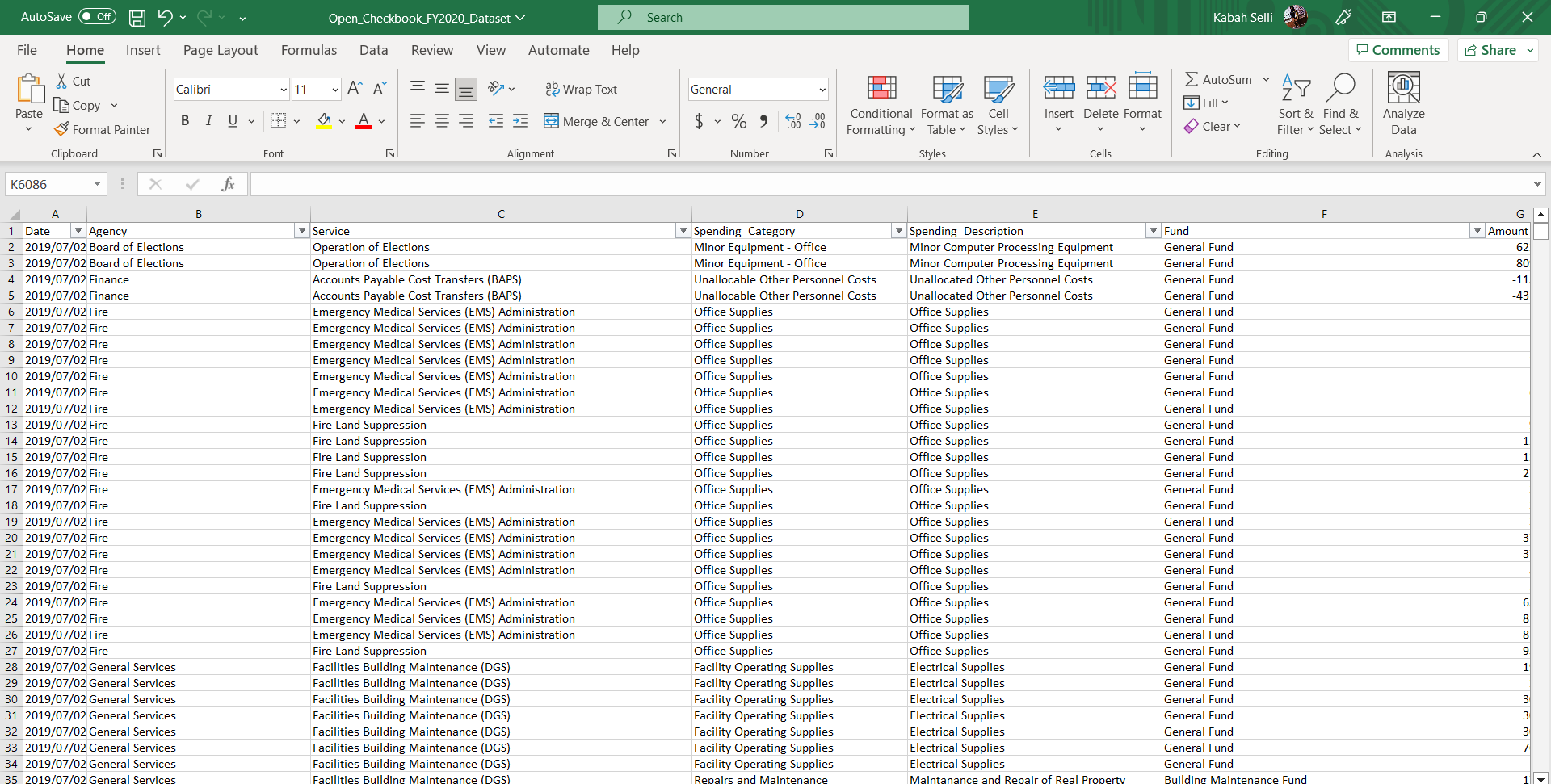
With this data in a much easier to work with format, my first goal was to manually see how I would be able to find an address using the present data. I first decided to choose a column to use as my search query, and the one I chose was “Service” column.
I decided to start with a small sample size of ten Services to manually run search queries using Google, of which I was able to find 10 addresses for each service, to varying degrees of difficulty.
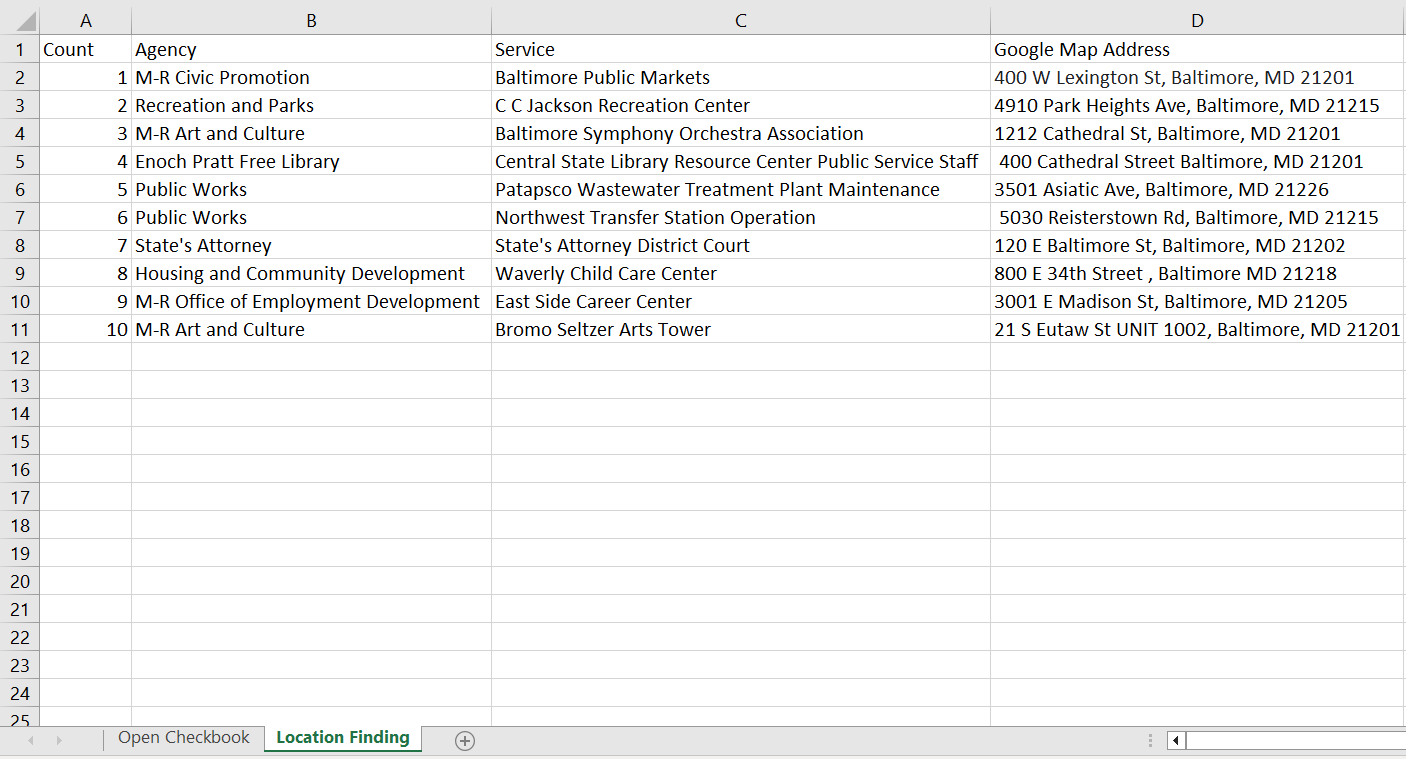
The purpose of this initial exercise was to ensure that it was in fact possible to find address information using information from The Database. As a result of this information, I added a new column to the OCB Database titled “Locations” wherein I added the ten addresses I found to the corresponding services. This resulted in 2707 rows worth of location information being added to the database (for reference, the overall database is composed of 174,976 rows).
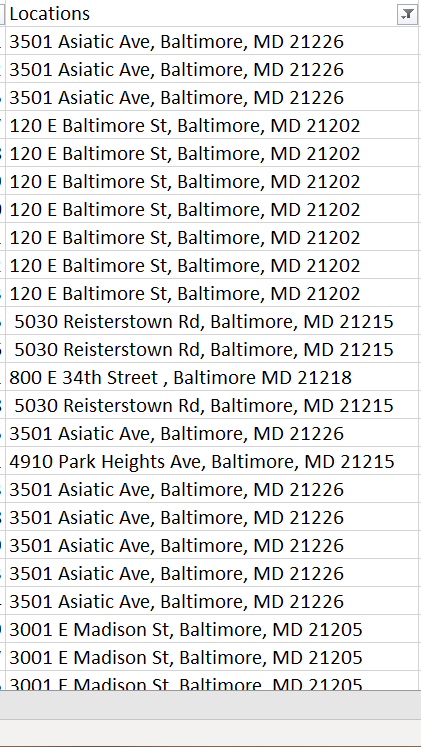
My next course of action was to develop a way to automate this process so that information within the database can be extracted, run through a program, have an address returned, then added to the location field within the database. In order to do this, I delved into Web Scraping, which is a technique that allows you to search within the source code of a webpage and extract specific kinds of data. In the case of this project, I utilized web scraping in order to find location information in the form of an address. To conduct this web scraping I decided to use the Python programming language as my medium to facilitate the web scraping, as it would’ve allowed me to make this an automated process and aid in the replicability of my findings. I am adept at using Python but not for web scraping so this was an opportunity to expand my understanding of the language using a new concept. Python as a programming language has a lot of benefits for such a project due to its open-source nature. What this entails is that through the internet I was able to access libraries of programs and functions created by other people that enhance Python and allow me to create more complex programs in contrast to the base Python package.
One library in particular that was integral to this project is called Beautiful Soup, also referred to as BS4. This Python library is the most used web scraping library for parsing through HTML code, which is what websites are composed of. So, the idea was then to input the URL of a website into a program using BS4 and then it will output the raw HTML components, of which can be combed through for various forms of information. In the context of this project, it allows me to find an address associated with the services listed in The Database. In conjunction with Beautiful Soup, pictured below are all the libraries I imported into Python to aid in creating this program:

After making that discovery, the plan was then to create a visual for the newly discovered data. In order to do so, I learned and practiced using a handful of data visual programs and applications. The next part of the plan was after adding the new location data to the OCB database, to attempt to recreate Baltimore City’s Power BI dashboard but with the inclusion of an interactive map. With programs like Power BI, Tableau, and ArcGIS at my disposal I would’ve been able to create an interactive map that would’ve allowed users to select a specific location wherein they can see all the services completed in the area of interest. Ultimately, it would have broken down the spending of the city by location.
Results:
The results of my project yielded some great discoveries and information, yet it wasn’t exactly as complete as I initially had planned. In the end I managed to set up a Python program that ran and returned internet search queries through Google API, added information to an Excel spreadsheet, and parsed through the HTML code of a webpage, finding and returning an address. Unfortunately, in the time allotted for the project, I wasn’t able to put together an interactive map or add every single address to the OCB Database. Nevertheless, below elucidates what I managed to accomplish.
Google Search Queries:
First is the Google Search Query section of the program. Pictured below is the portion of the program that allows for a user to enter a word, phrase, or sentence into the program, which takes that user input and converts it into a variable named “query”. This query variable containing what the user inputted is then ran through a for loop that will use Google search engine API (Application Programming Interface; in this context, the programming that allows Google to be able to search the internet) and returns a Google search result as a hyperlink. I have the for loop set to iterate ten times in order to produce a list of ten search results (Ten was an arbitrary number chosen just to get a decent sample size to verify the return URLs were the same as if you had manually Google the query).
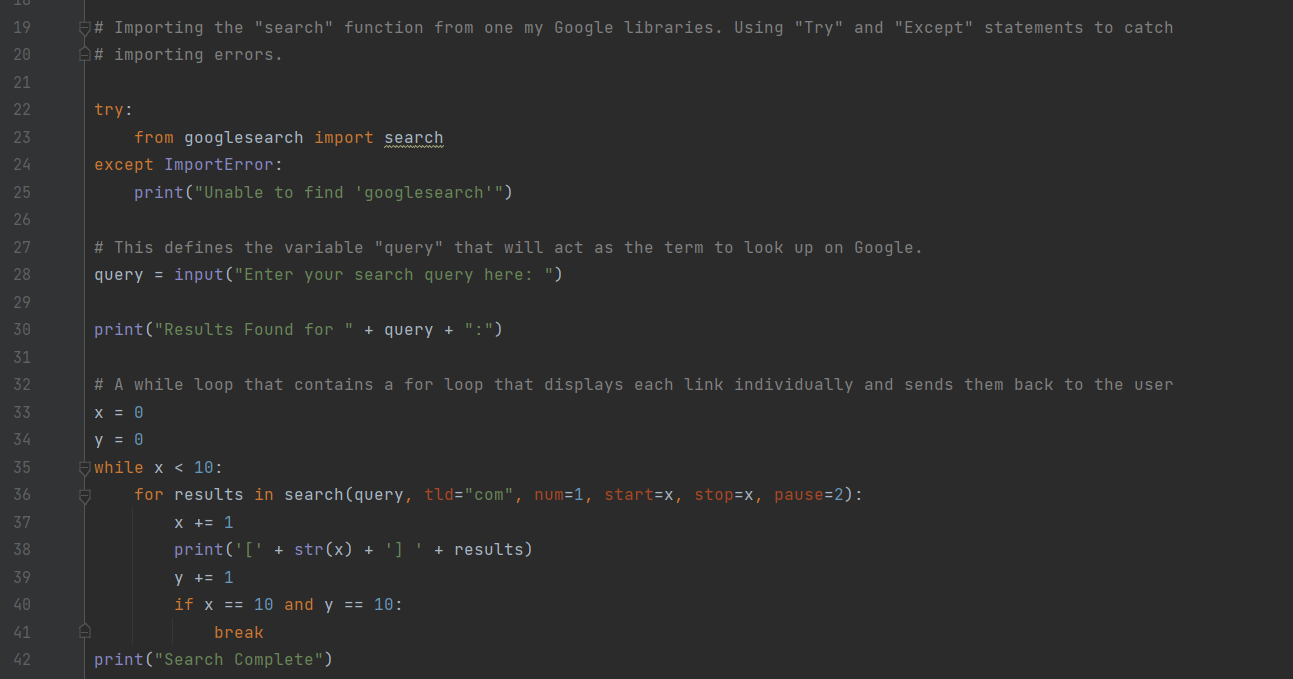
Below is the output displayed to the user, and as can be seen it’s a nicely numbered list of ten hyperlinks that will lead to websites relevant to the search query. In this example, I made the search query “Bromo Seltzer Arts Tower” which was one of the initial ten test services I chose above.
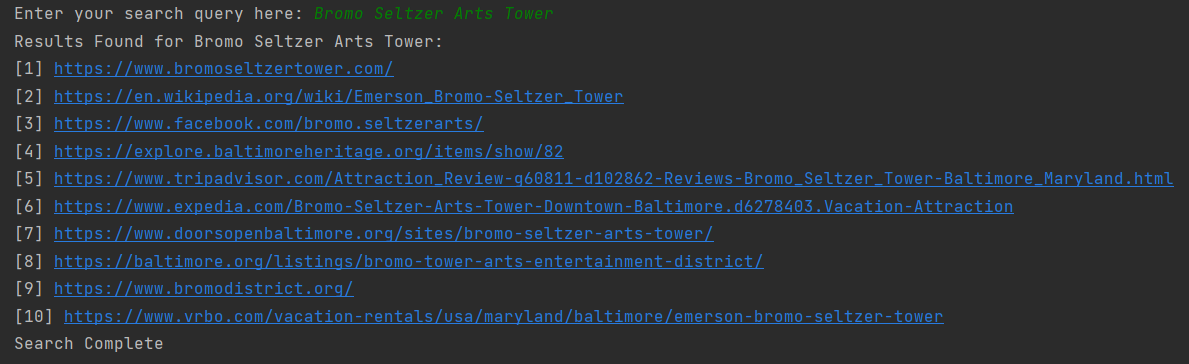
Edit An Excel Spreadsheet:
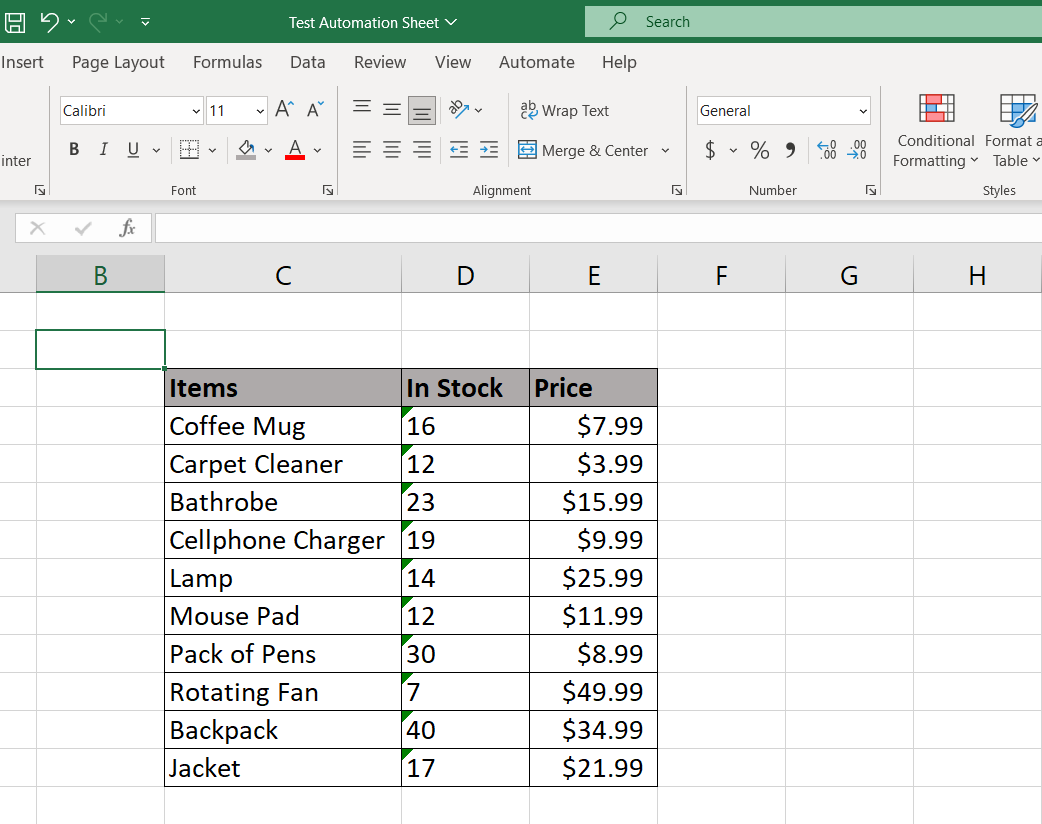
Next is the Editing an Excel Spreadsheet section of the program. Picture below is a test Excel file I made to display this portion of the program which adds information into an existing Excel file/ database. It’s a mock inventory list with item names and prices listed, however the column labeled “in stock” is empty with no data, this is where the program comes in.
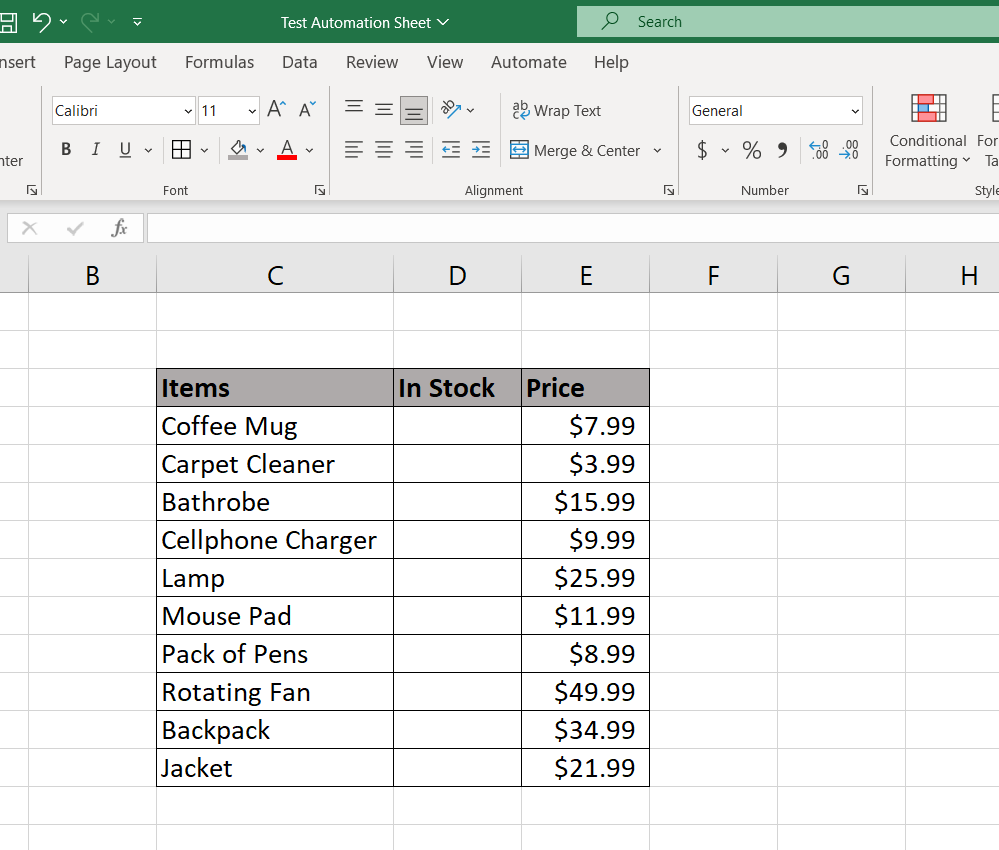
The next images show the functionality of the program. It firstly opens the chosen Excel file, in this case its “Test Automation Sheet.xlsx”. The program then declares the variable “book” which stores the information for the Excel file. The program then declares another variable called “sheet” which holds the information for the current active sheet within the file. What that means is that the program will make changes in the main sheet where the mock inventory is stored. The program will then treat the variable “sheet” as an array, which is a special variable that stores a list of elements, with the elements in this case being the cells of the Excel file. With the Excel cells chosen, as indicated by the square brackets, the program then assigns a value for each cell. After all values are added to the cells within the Excel file, the program saves the changes, then informs the user of the change. (for the sake of being able to follow the process of the program, I included print statements that would indicate the current status of the program.)
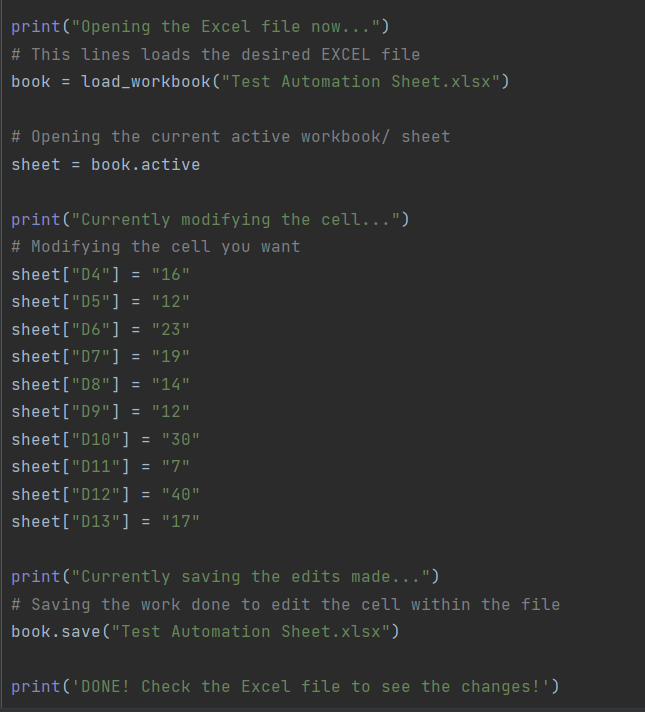
Pictured below is the result of the changes made by the program, as can be seen, the blank “in stock” column from before now has values within it (note: the reason Excel displays the values like that is because the formatting wasn’t correct; the numbers were entered to Excel as “text” rather than as a numerical value, this was done just for the sake of avoiding unnecessary decimals. What would then be done here is someone do some brief data cleaning to make sure the data was properly formatted).
Web Scraping/ Parsing Through HTML Code:
Lastly, but not least is the BS4 web scraping section of the program. Pictured below is the main code that does the web scraping/ parsing through the HTML code for the desired information. In the context of this project, this is the code that searches through webpages, via provided URLS, and returns location data in the form of an address.
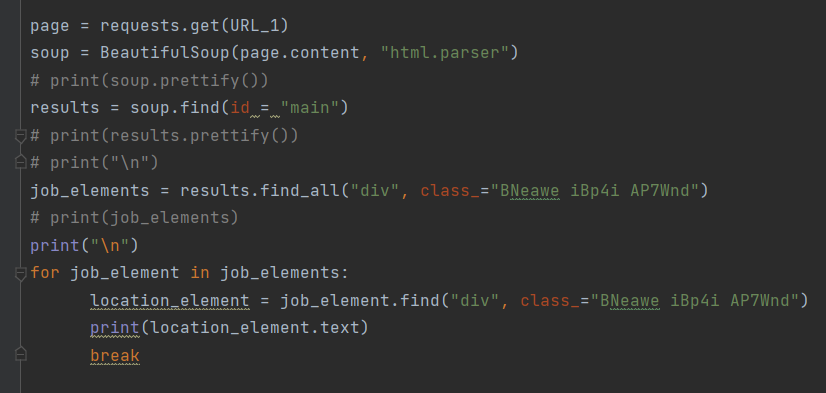
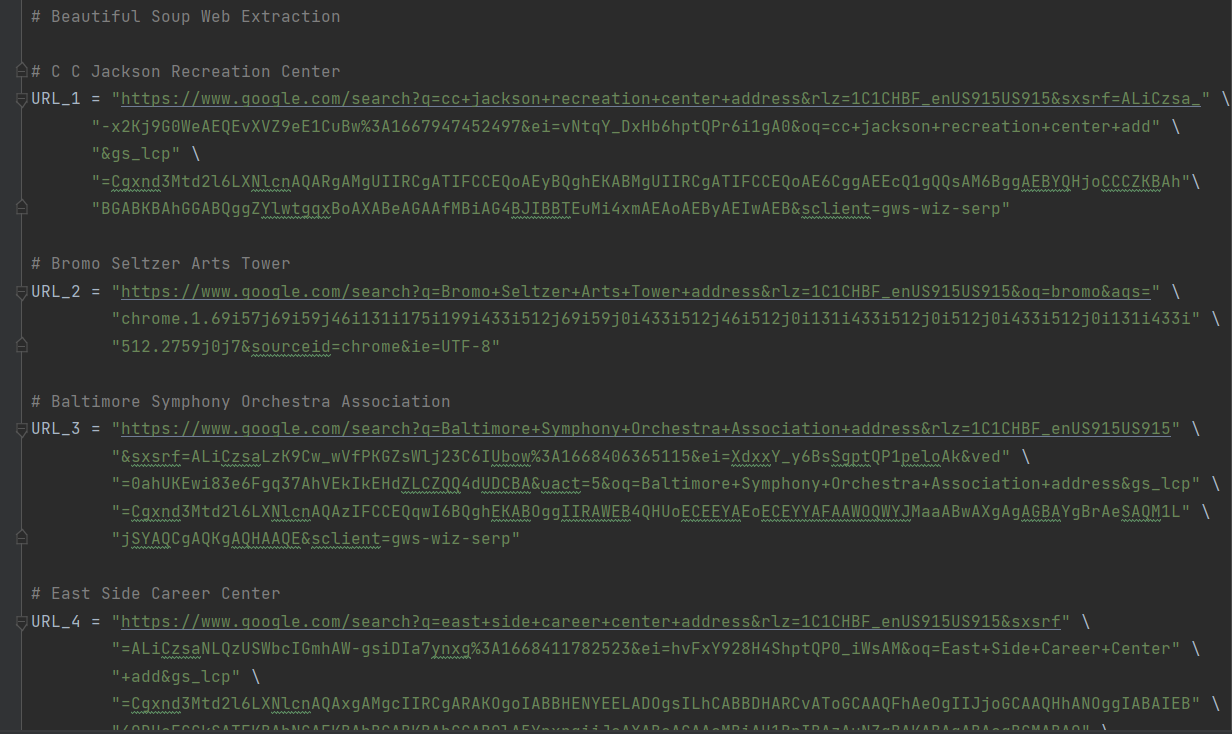
The first thing I do is declare the variable known as “URL_1” (there are 5 total variables that are all different URLs, but for simplicity I am only referring to the first URL within the variable “URL_1”). The variable contains a URL from a manual Google search I made with the search query “C C Jackson Recreation Center address” wherein I was met with a page that looks like this.
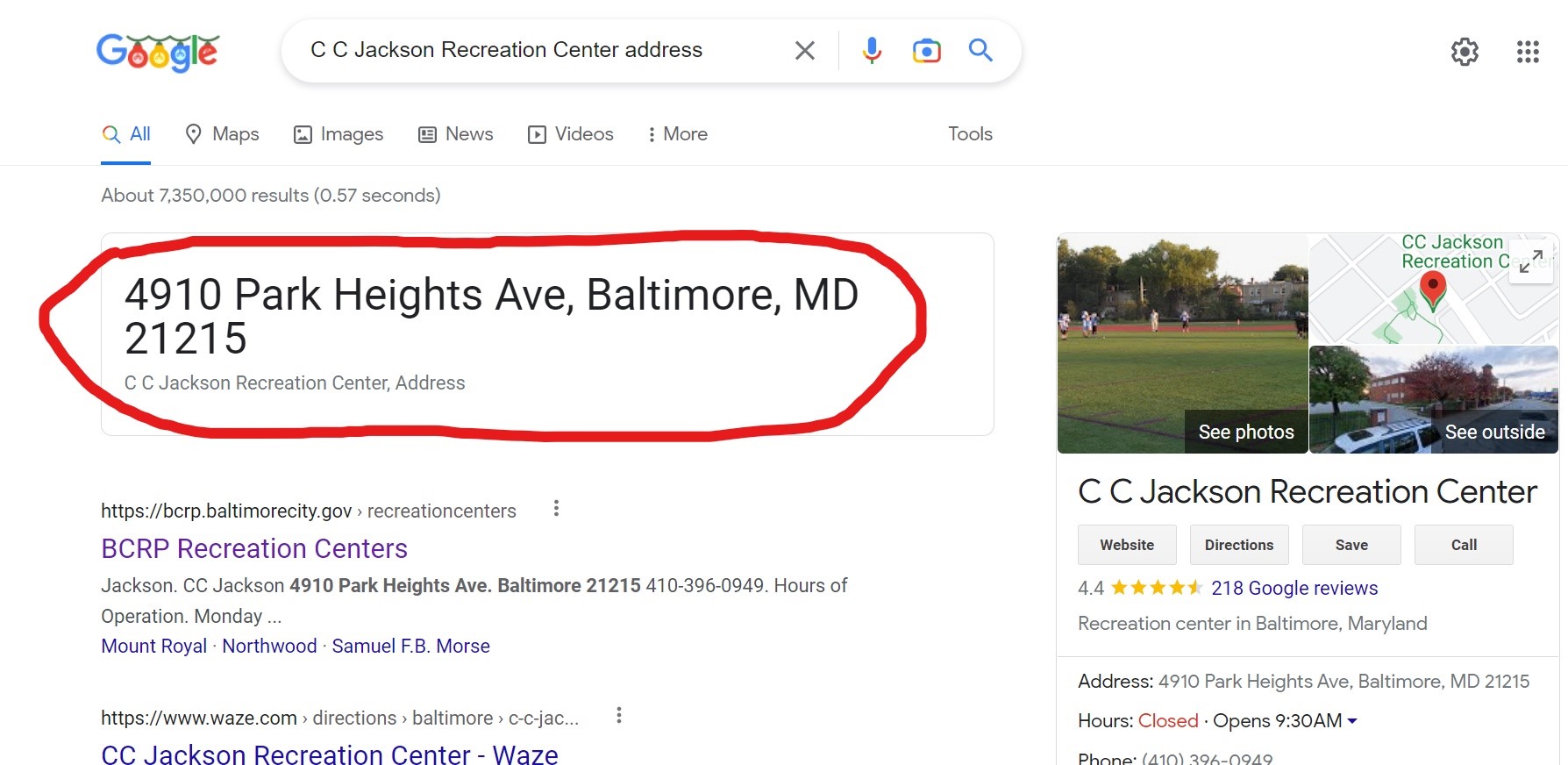
The section circled in red was the information the program was to return as an output. In order to do that I had to find out what that element was named within the HTML code in order for the program to extract the address information. After using F12 on that webpage to look at the HTML source code, I found it was a class named “BNeawe iBp4i AP7Wnd” and with that I entered it into the web scraping code and the results were as followed:
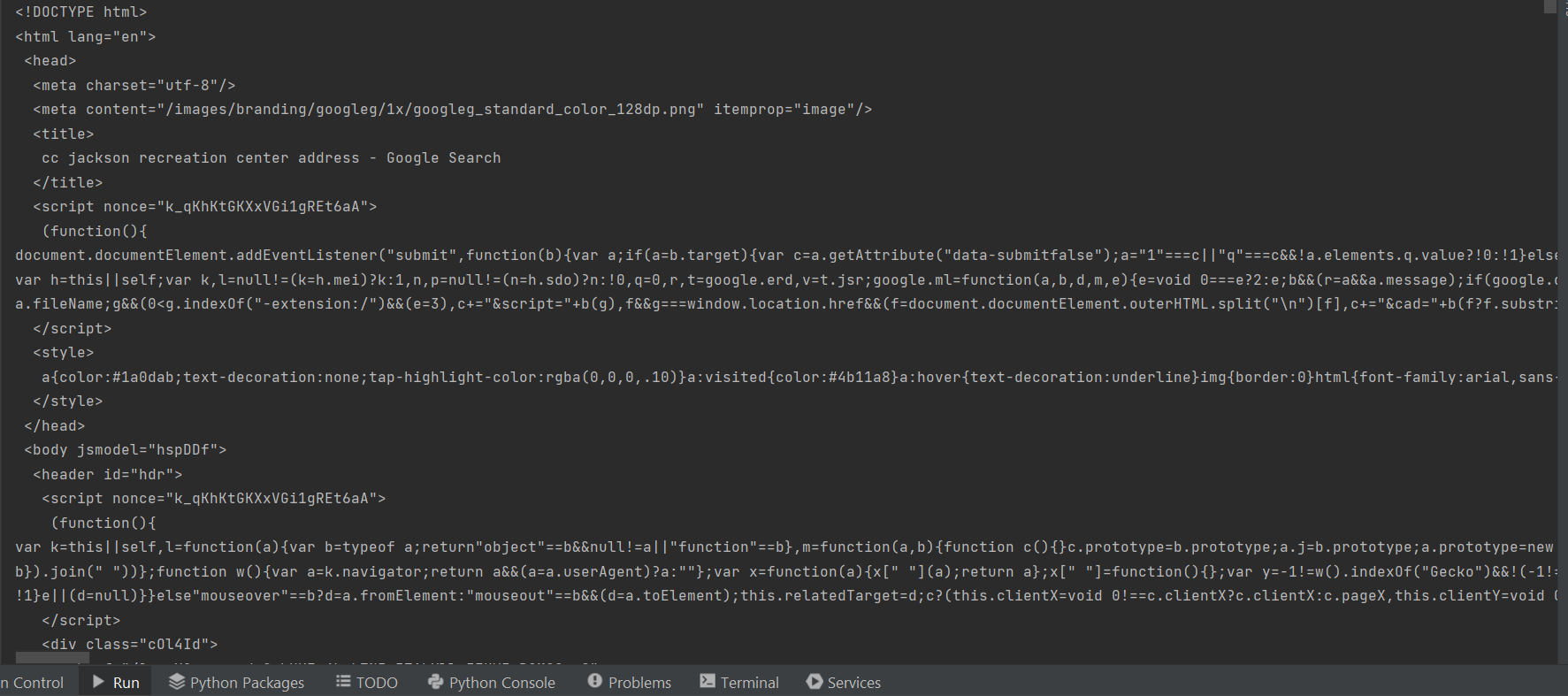
(Pictured above is the entire HTML code for the webpage)

(Pictured above is the specific line from within the HTML code that contained the class “BNeawe iBp4i AP7Wnd”, and even from this point the address for the location is visible.)

(Pictured above is the address fully extracted from the HTML code and properly formatted for future use.)
This part of the program, which for all intents and purposes was both the most difficult part to figure out and the main function needed, was successful and exhibited that it is in fact possible to extra location data in the form of an address from an URL/ online webpage. Being mindful however, this was a rather specific instance where the URL was handpicked by me and also was tailored with the address in mind. Through other tests, not all search queries resulted in the same success.
Ultimately, while I wasn’t able to create a single concise and fluent program where each part feeds directly into one another. Nonetheless, the groundwork is there for that possibility because the idea was to have use the Google Search Query section to enter a phrase like “Bromo Seltzer Arts Tower address”, then it’ll return relevant URLs that contain an address. It would then take the most relevant/ first URL and run it through the Beautiful Soup Web Scraping section, of which would, hopefully, return an address. Lastly, it would run the address through the Excel spreadsheet editor section wherein it would add the address to the OCB spreadsheet/ database wherein by that point the OCB may have a simple sorting algorithm within the Excel spreadsheet that would pair the correct address to its intended service. In theory, this is the full functionality of my program but in practice I created the main components of that process, but unfortunately was unable to link them together.
Key Takeaways:
After having worked on this project for the three to four months I spent as a Data Science Corps Intern, I was able to gain an invaluable myriad of skills, techniques, and knowledge. Much of what I learned in the program will be applicable to my future career; skills in Data Science, Data Visualization, Geographical Information Systems, Statistical Analysis, Web Scraping, Data Cleaning, Data Indicators, and APIs. While I wasn’t able to completely finish all I had originally set out to do, the work I was able to complete still has its implications and uses for future projects, namely the potential automation of Web Scraping through the use of search queries. Research like this, even if not fully finished, is something I am proud to have been able to produce both to show my own capabilities and the value of a program like the Data Science Corps. If there was anything I would do differently, I would’ve been to try and narrow my focus earlier on within the project, that said I am able to say this with hindsight of how things turned out. At the time, it was well understood that the area I was entering was rather experimental and we weren’t sure if it was even possible to accomplish every single set objective that was outlined within this blog, but at the very least going in pretty much in the dark with the possibilities and potential finds with hopes of a program that would speed up much data science and web scraping work, I would say for what I was able to come up with I definitely am proud to have even produced what I did.
Conclusion:
Ultimately, I was able to answer the data science question of “Is it possible to extract/ generate location data from a pre-existing database?”, the answer is yes. That said, the manner in which I found that answer still has much room for improvement, as I have stated already. Though, as far as this new data generated from the OCB Database, I’m sure if the Mayor’s Office or a department in the City of Baltimore were to acquire this program it would be beneficial in both developing new fields and data for their Database, but a lot of the techniques used here would aid in bolstering other technological areas. It would allow for them to be more efficient in utilizing Excel files, give another tool when creating metrics from online local websites, and even add a level of automation that could not only save time, but money. In the end, the project was still a success in terms of how it adds new knowledge to various disciplines of data science as this project covered topics from Web Scraping to Coding to Data Visualization. I am extremely glad to have been able to work on a project like this and also find out such interesting ways of using data.
Next Steps:
There are still many possibilities for what’s to come next for a project like this. I have already outlined a path of completion where I or someone else would be able to connect each component and create a seamless automated web scraper that returns desired data based upon the search queries extracted from a pre-existing database. Another way to further progress the work done within this project is to create a system where you can create an Excel spreadsheet containing a set of data and have the program new fields composed of web scraped online data, this may even be a great chance to introduce some machine learning and make automatic database creators. The program would both create and fill in fields with data returned via online search queries. It may seem rather farfetched, but again, it’s just about the implications such data science work can have if taken well beyond my own capabilities. While these are just some examples and hypotheticals, with the groundwork laid within this project, it is very likely that these types of end results and highly complex projects can become achievable.
References:
Beautiful Soup: Build a Web Scraper With Python: https://realpython.com/beautiful-soup-web-scraper-python/
Changing Values in Excel Using Python: https://www.geeksforgeeks.org/change-value-in-excel-using-python/
Geonames: https://www.geonames.org/
Google Maps Platform: https://developers.google.com/maps
Google Searching using Python: https://www.geeksforgeeks.org/performing-google-search-using-python-code/
Guide to Parsing HTML with BeautifulSoup in Python: https://stackabuse.com/guide-to-parsing-html-with-beautifulsoup-in-python/
How to Update Excel Files Using Python: https://medium.com/gustavorsantos/how-to-update-excel-using-python-f2d24bab7922
How to get URL from chrome by Python [duplicate]: https://stackoverflow.com/questions/57900225/how-to-get-url-from-chrome-by-python
Improving the Accuracy of a Web Scraper by Logan Shertz: https://bniajfi.org/2021/11/17/improving-the-accuracy-of-a-web-scraper/
Modern Web Scraping With Python and Selenium: https://www.toptal.com/python/web-scraping-with-python
Nominatim: https://nominatim.openstreetmap.org/ui/search.html
Open Street Maps: https://www.openstreetmap.org/#map=19/32.78935/-117.09804
Python OpenPyXL Tutorial: https://www.youtube.com/watch?v=U3LsqdjRvzw
Update Column Value of CSV with Python: https://www.geeksforgeeks.org/update-column-value-of-csv-in-python/
Web Scraping with Beautiful Soup: https://www.geeksforgeeks.org/implementing-web-scraping-python-beautiful-soup/